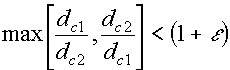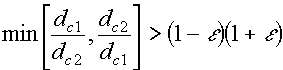|
LVQ
LVQ Training Algorithm:
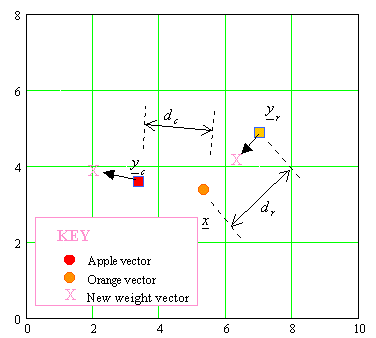
NOTE: EXAMPLE: APPLES AND ORANGES Suppose we measure the weight and
height of three apples and three oranges. The input vector
EXAMPLE: THREE CLASSES Suppose there are three classes { red, blue and green}. The applet animation below shows how an LVQ with two neurons per color, is able to adjust the weight vectors of its neurons so that they become typical red, blue and green reference or codebook vectors. As in the previous example, the input vector x has only two elements, which can then be shown on a 2D plot.
EXAMPLE
TRAINING Take the first two input vectors (since only 2 categories) to set the weight vectors as follows:
Let us set
For the input vector 0011
Hence J = 2 since Now since
For the input vector 1000 Find J = 1 Now since
For the input vector 0110 Find J = 1 Now since
STEP 5: Now reduce the learning rate STEP 6: Test Stopping condition. : This may be a fixed number of iterations (excluding step 0 of course) or the learning rate reaching a sufficiently small value |
|
LVQ2 : First Improvement Let Let Let Let Let Both vectors are updated if all of the following three conditions are satisfied:
If the above three conditions are satisfied, then
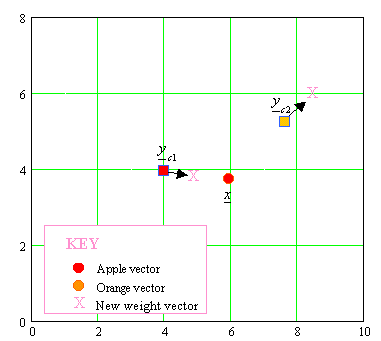
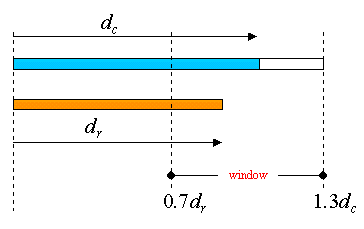
EXAMPLE: APPLES AND ORANGES
LVQ2.1 : Second Improvement Consider the two closest
reference vectors The requirement for updating
these vectors is that one of them belongs to the correct class (for the
current input vector
If these conditions are met, and
suppose
and the reference vector that
does not belong to the same class as
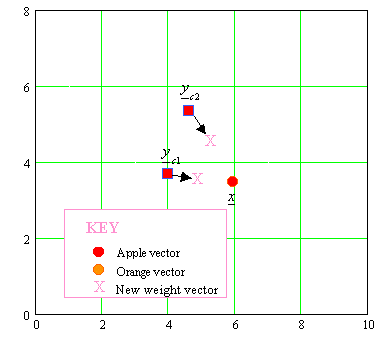
EXAMPLE: APPLES AND ORANGES
LVQ3 : Third Improvement Allow the two closest vectors to learn if the following condition is met:
EXAMPLE: APPLES AND ORANGES
|
Reading paper:
An online learning vector quantization algorithm
A methodology for constructing fuzzy algorithms for learning vector quantization
.files/Image1165.gif)
.files/lvq.gif)
.files/lvq2gif.gif)
.files/fig2.gif)
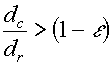 AND
AND 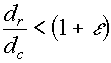
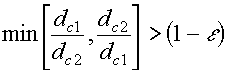 AND
AND